The organisers of the 66th IEEE Symposium On Foundations Of Computer Science (FOCS) 2025 asked me to construct a cryptic crossword for the event.
Here it is. Enjoy.
FOCS 2025 Cryptic Crossword
Leave a reply
The organisers of the 66th IEEE Symposium On Foundations Of Computer Science (FOCS) 2025 asked me to construct a cryptic crossword for the event.
Here it is. Enjoy.

Summary of my keynote talk on 4 November 2021 at the eponymous Norwegian national conference Nasjonal konferanse: Digitalisering i høyere utdanning 2021, hosted at Bergen University and organised with the Norwegian Directorate for Higher Education and Skills. The summary is somewhat disjointed and includes some of the slides.
The first part of the talk is about the potential use of digital technology to improve learning outcome in specific contexts. When I gave the talk I showed a bunch of ephemeral examples that I had used myself, or which seemed otherwise cool, instructive, useful, or exciting in late 2021. These examples won’s stand the test of time, so I won’t repeat them here. A well-known and old example that everybody knows is the language learning application Duolingo.
Benefits include immediate feedback, scalability, transparency of assessment, accessibility, spaced repetition, and individual pacing or tracking of material. Common to the contexts where digital technology seems to be largely beneficial are
More problematic are assistive technologies, often using machine learning or other forms of decision-making processes collectively known as artificial intelligence, that ensure surface conformity of written material. These have clear benefits for authoring but also equally clear negative consequences for assessment. Modern word processors allow the production of professional-looking prose and automate surface markers of quality (layout, grammar, style, phrasing, vocabulary), which traditionally were used as proxies for content in assessment of learning outcomes; online natural language processing services like Google Translate invalidate traditional forms of language proficiency assessment based on written material. In 2021, a beta version of the programming environment GitHub Copilot automatically solves programming exercises from the task description. The same tools that perform plagiarism checks can also plagiarise very well.
So there is stuff that becomes somewhat easier by digitisation (transmission of knowledge), and where we have many ideas for what to do, and stuff that becomes much harder (valid assessment), and where we have very little idea about what to do.
A third theme is stuff that does become easier, but maybe oughtn’t. This is found under the umbrella education data mining – predicting student performance, retention, success, satisfaction, achievement, or dropout rate from harvested data such as age, gender, demographics, religion, socio-economic status, parents’ occupation, interaction with application platform, login frequency, discussion board entries, spelling mistakes, dental records, social media posts, photos, and everything else. The promise of this field—and in particular, machine-learned predictions based on polygenetic scores—is enormous; and there is an emerging literature of success stories in the educational literature. I strongly dislike this trend, but that’s just, like, my opinion.
This summaries the first part, with the foci
There are of course a ton of other problems, which I expanded on in the full talk:
I’m pretty confident about part 1 (digitisation for education), and return to a confident stance in part 3 (education for digitisation). In contrast, part 2 is characterised by epistemic humility. It’s my best current shot at what makes the whole topic hard do think about.
Over the years I have learned a lot about “How to think about digitisation” from the DemTech project at IT University of Copenhagen, which looks at digitisation of democratic processes, in particular election technology. “How to digitise elections” is a priori an easier problem than “How to digitise higher education”, because the former is much more well-defined. Still, many of the same insights and phenomena apply.
These problems include a (largely unhelpful) eagerness of various stakeholders to digitise for the sake of it. An acerbic term for this is “magical IT gravy”:
[…] politicians who still think that you can just drench a problem domain in “magical IT gravy” and then things become perfect.
Poul Henning Kamp, 2021

Briefly put, if you digitise domain X then you will digitise your description of X. (A fancy word for this is reification.) Since (for various reasons, including lack of understanding, deliberate misrepresentation, social biases, status, and political loyalty) the description of X is seldom very good, digitisation reform typically deforms X. Since digitisation is seen as adaptive within organisations, it bypasses the converstations that such transformation would normally merit.
My ITU colleague Carsten Schürmann showed me this insightful taxonomy:

Let’s use voting as a concrete example to talk us through this. At the bottom is Functionality: voting is to increase a counter by 1 every time somebody casts a vote. This is easy to implement, and easy to digitise; any programmer can write an electronic voting system. Above that is Security: making sure the voting process is free (i.e., secret, private, non-coerced, universally accessible, etc.) This involves much harder computer science, for instance, cryptography. You need to have a pretty solid computer science background to get this right. Above that tier is Validity: how do we ensure that the numbers spat out by the election computer have anything to do with what people actually voted? This is even harder, in particular without allowing coercion by violating secrecy. (Google “vote selling” if you’ve never thought about this.) Finally, after thinking long and hard about all these issues (which by now include social choice theory, logic, several branches of mathematics) you arrive at what elections are actually about: Trust. The overarching goal of voting it so convince the loser that they lost. And this requires that the process is transparent.
Applications at the Functionality stage are easy (if you’re a competent programmer), they are mono-disciplinary, and the happen by themselves because geeks just want to see cool stuff work. The higher up you go in the hierarchy, the more disciplines need to be included, so the requirement for inter-disciplinary work increases. An organisational super-structure (such as a university) is needed to incentivise and coördinate the things at the top.
To translate the above model from voting to Higher Education, the Functionality part is transmission of knowledge: all the cool and exciting ideas I mentioned in part 1. Security corresponds to preserving privacy of learners throughout their educational history; this already conflicts with both educational tracking (e.g., for individualised progression) and reporting (e.g., for credentials). The first steps, probably in the wrong direction, can be seen by universities in Europe reacting to the European GDPR legislation, which already takes up a significant amount of organisational resources. This layer is correctly seen as annoying, depressing, time-consuming and boring, but still outshines in enthusiasm the next layer: Validity. The very features of information technology that make it incredibly useful for transmission of knowledge (speed, universality, faithful copying, depersonalised expression, accessibility, bandwidth) make it incredibly difficult to perform valid assessments, in particular in high-stakes, large-scale exams of universal skills. This is because digital technology makes it it is very easy to misrepresent authorship and originality. (Think of playing the violin, drawing, programming, parallel parking, mathematics, translating between languages—which digital artefacts would constitute proof of proficiency?)
Yet this is all still manageable, and some universities or educational systems may even choose to get this right. For instance, I think I know that to do.
But the really Hard Problem of Digitsation is the one at the top of the hierarchy: What is higher education even about?
I don’t know the answer to that.
Here are some possible answers. Maybe they’re all correct:

The narrative I tell myself is very much the first one, the capital-E Enlightenment story of knowledge transmission, critical thinking, and a marketplace of ideas. We can call this the Faculty view, or Researcher’s, or Teacher’s. The Economist’s view in the 2nd row is, thankfully, largely consistent with that; it’s no mystery that the labour market in knowledge economies pays a premium for knowledgeable graduates—the two incentives are somewhat aligned. (It does, however, make a big difference in how important transmission of knowledge and validity of assessment are in relation to each other. Again, “why not both?” and there is no conflict. Critical thinking versus conformity is a much more difficult tension to resolve.)
Still, the question whether Higher Education creates human capital (such as knowledge) or selects for human capital is (and remains) very hard to talk about among educators. Very few teachers, including myself, are comfortable with the idea that education favours the ability to happily and unquestioningly perform meaningless, boring, and difficult tasks exactly like the boss/teacher wanted (but was unable/unwilling to specify honestly or clearly) in dysfunctional group, and that it selects for these traits by attrition. Mind you, it may very well be true, but let’s not digitise that. (I strongly recommend Bryan Caplan’s excellent, though-provoking, and disturbing book The Case Against Education to everybody in education.)

The two other perspectives on what Higher Education is about (Experiental, Social, both are Student perspectives) are much more difficult to align with the others. Students-as-consumers-of-an-experience (“University is Live Role Playing”) and students-as-social-primates (“University is a Meet Market”) have very different utility functions than both Faculty and Economists.
The point is: if we digitise the phenomenon of Higher Education, we need to understand what it’s about. (Or maybe what we want it to be about.) Currently, Higher Education seems to do a passable job of honouring all four explanations. I guess my position is largely consistent with Chesterton’s Fence:
In the matter of reforming things, as distinct from deforming them, there is one plain and simple principle; a principle which will probably be called a paradox. There exists in such a case a certain institution or law; let us say, for the sake of simplicity, a fence or gate erected across a road. The more modern type of reformer goes gaily up to it and says, “I don’t see the use of this; let us clear it away.” To which the more intelligent type of reformer will do well to answer: “If you don’t see the use of it, I certainly won’t let you clear it away. Go away and think. Then, when you can come back and tell me that you do see the use of it, I may allow you to destroy it.”
G.K. Chesterton, The Thing (1929)

Even if we (as educators and educational managers) were to understand what education is about, and even if we were agree on good ideas for how to proceed, none of us lives in a world where good decisions are just made. We have to communicate with stakeholders who are themselves beholden to other stakeholders, and need to understand that these individuals live in a complicated social or organisational space where they are evaluated on their individual, institutional, or ideological loyalty. Not on the quality of their decisions.
We must expect most organisations, including most universities, to make decisions about digitisation in higher education that are based on much more important factors (to the stakeholders) than “whether it works”. Given the choice between trusting the advice of a starry-eyed snake-oil salesman (or, in our case, a magical IT gravy salesman) and a reasonable, competent, experienced, responsible, and careful teacher, most responsible organisations will choose the former.(!) The feedback loops in education are simply too long to incentivise any other behaviour.
The last part of the talk—about how to prepare higher education for digitisation—is really short. Because (I believe) I know what to do. I consider it a solved problem.
Here is the list of things to do:
That’s it.
Basic programming is teachable, it is mostly learnable by the higher education target demographic, is easily diagnosed at scale, works extremely well with digitisation-as-a-tool, is extremely useful now (in 2021), applies to many domains, will likely be even more useful in future, and in more domains, is highly compatible with labour market demands, and an enabling tool in all academic disciplines.
If you’re on board with this, my best advice for anyone with the ambition to teach basic programming is to adopt the following curriculum:
Point 2 is really important. In particular, my advice is to not add contents like applications, history of computing, ethics, societal aspects, reflection, software design, project management, machine learning, app development, human–computer interaction, etc. Mind you, these topics are extremely interesting, and I love many of them dearly. (And they should all be taught!) But unless you are a much better teacher than me, you will not be able to make the basic programming part work.
That’s it. The full talk had better flow, included some hands-on demonstrations of cool applications, and had more jokes. I am really grateful to the organisers for giving me the chance to think somewhat coherently about these issues, and had a bunch of very fruitful and illuminating conversations with colleagues both before and after the talk. I learned a lot.
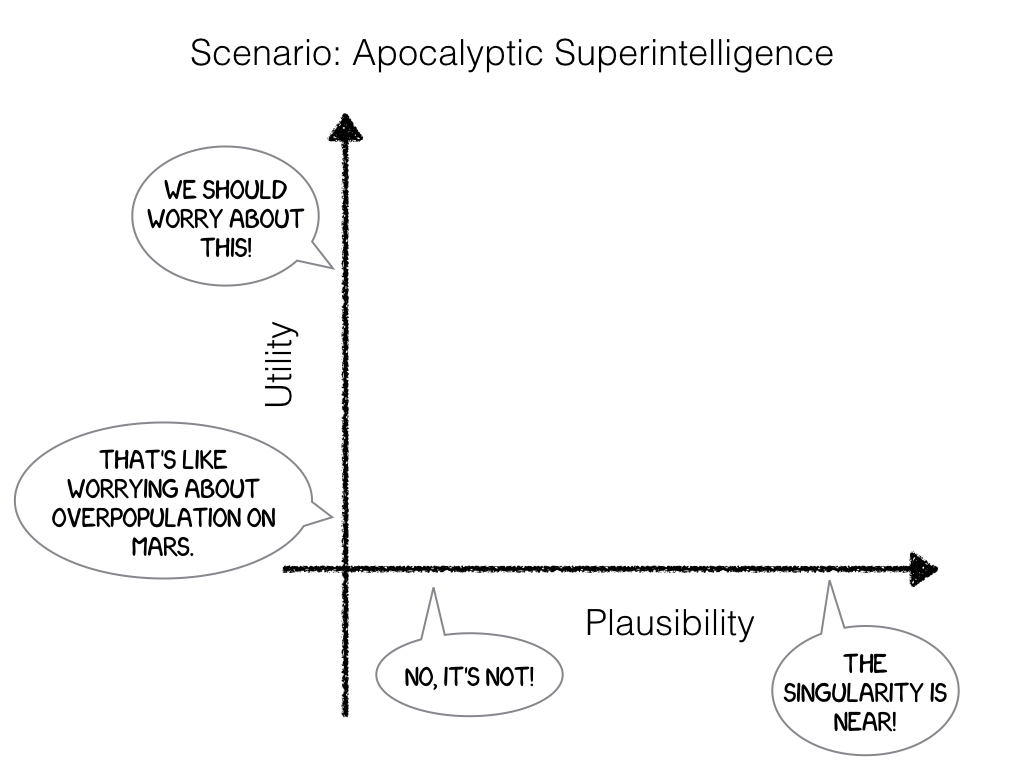
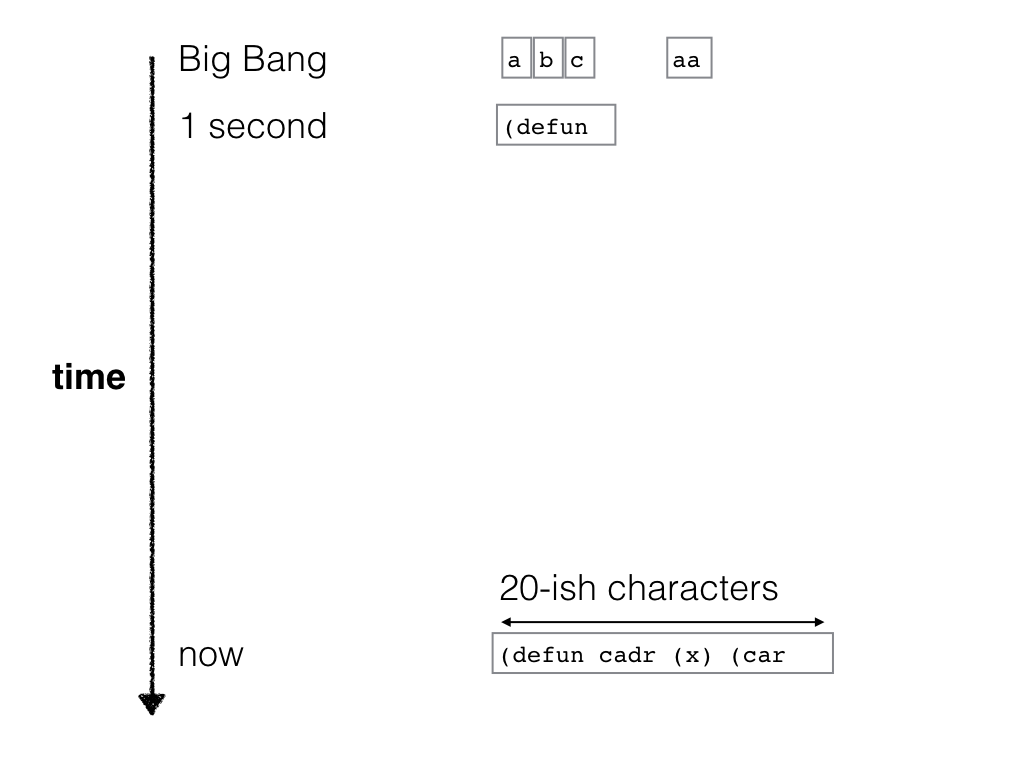
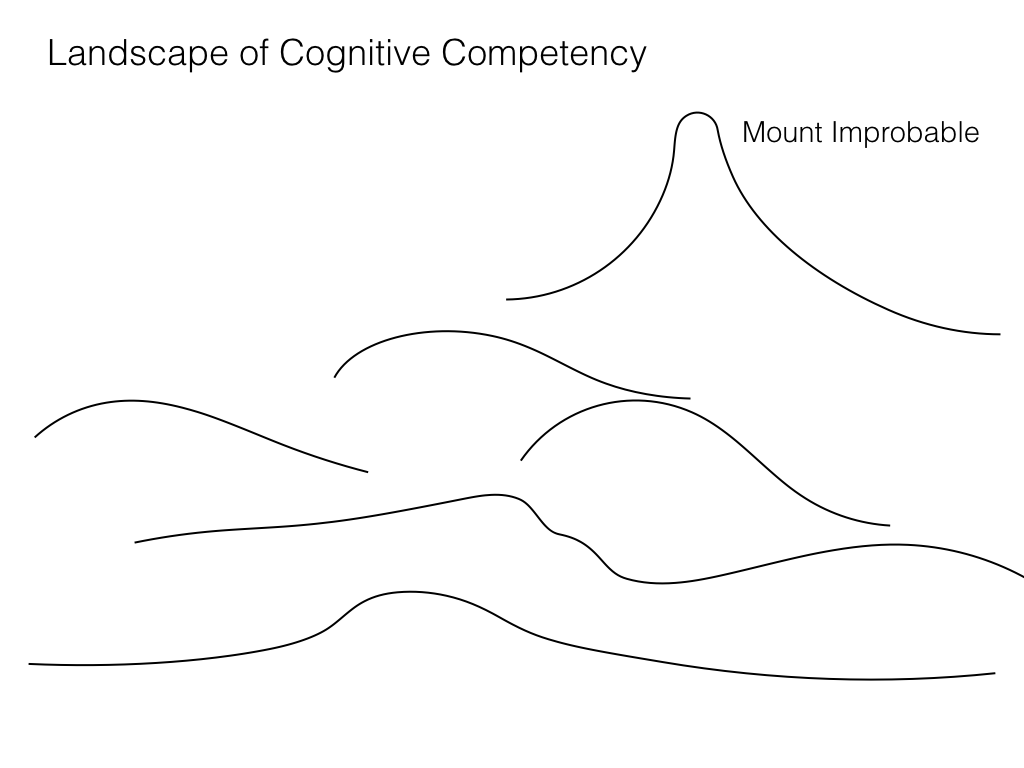
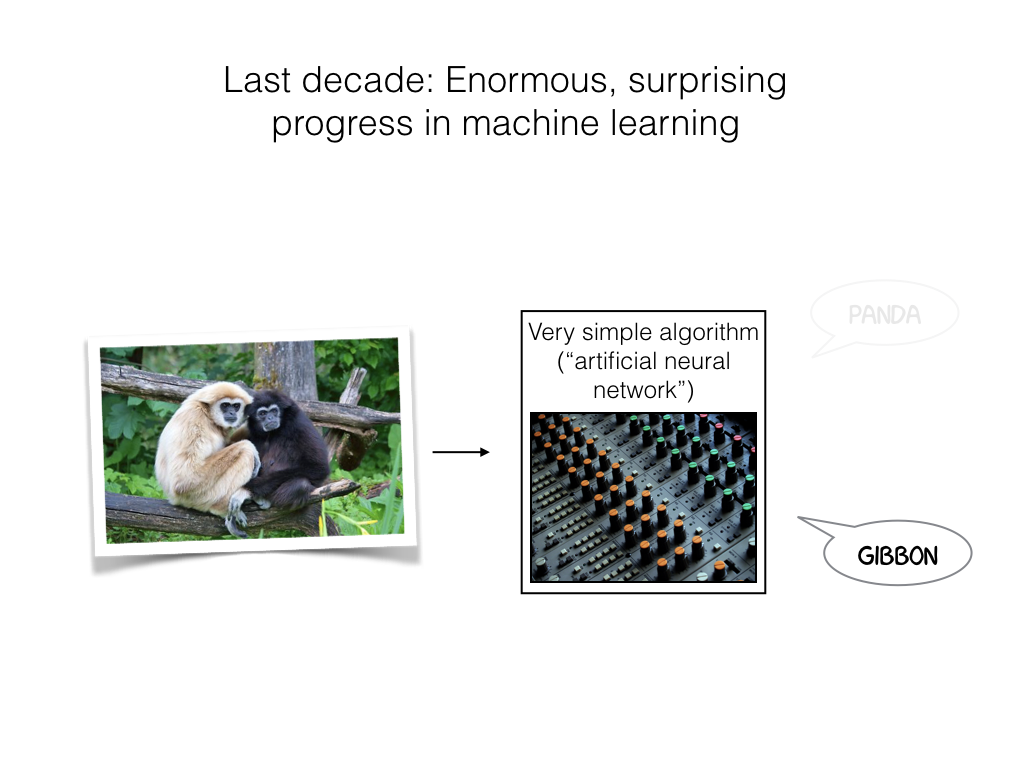
Talk given at the GoCAS workshop Existential Risk to Humanity, Gothenburg, 7 Sep 2017.
Video recording of presentation at YouTube
Slides:





































I spent a splendid week at Schloss Dagstuhl for Dagstuhl Seminar 14451: Optimality and tight results in parameterized complexity. As usual, this was intellectually extremely stimulating and very exhausting.
My head is full of tempting research ideas that I immediately need to pursue. Instead, I finalised a small cryptic crossword about parameterized complexity. If you are in the tiny demographic targeted by this puzzle, enjoy!

Across
7 Freethinker Nelson hides a smaller problem. (6)
8 Mr No is crazy for graphs like K5 and K3,3. (6)
9 Remote application for algorithm rejected initially. (4)
10 Uppermost parts of perennial Unix command for displaying acyclic graph in PostScript? (8)
11 Peer pressured? (8)
13 Gadget for viewing booty in the mirror. (4)
14 Leaders of Japanese universities lament yearly when ICALP is. (4)
15 The German left room before Erik Demaine briefly blushed. (8)
16 Holger Dell, perhaps, to date teen in disguise. (8)
19 At the start of reduction, apply a trick. (4)
20 Rod is covered in soft hair, reportedly. (6)
21 Importance of mean and variance, for instance. (6)
Down
1 Important concept in exponential time complexity is belittling to slave. (4-9)
2 A connected, bridgeless cubic graph with chromatic index equal to 4 expresses “I love you” in a sharply critical fashion. (8)
3 Leaf lattice contains a set whose closure equals itself. (4)
4 Aunt had intercourse, as represented on a surface. (8)
5 Sounds like you mend one. (4)
6 Unix filesystem in important kernelization. (13)
12 Ask wordy drunk when Dagstuhl seminars take place. (8)
13 Robertson and Seymour’s results maybe confused me and others. (8)
17 Blow nose for very long running times. (4)
18 At first, Eppstein liked minimum spanning trees. (4)

Illustration of Yates’s algorithm from my talk. I finally found a way to simultaneously depict the lattice structure and the symmetries of the circuit.
Many computer science fields in France are organised in national, cross-institutional groupes de recherches, not completely unlike the ACM SIGs in the US. The TCS group (“Mathematical Informatics”) encompasses some 400-500 people, as far as I understand.
As in most of Europe, theoretical computer science in France includes many more fields more than US-style theory of computation. Amazingly, they meet once a year for two days, and give well-attended talks to each other. The 2012 meeting had 170 registrants, an impressive number.
This struck me as particularly noteworthy after just attending SODA, where the various subfields of algorithms become increasingly fragmented and estranged, to the point of hostility and mutual incomprehensibility.
At the Paris meeting, a steering committee selects a number speakers from the various working groups in the GDR IM, who give meaty, 45-minutes talks to a general TCS audience: Computational logic, computational geometry, distributed systems, process calculi, extremal graphs, ….
In addition, the meeting includes two 1-hour invited talks recruited outside of the French GdR. Ashwin Nayak talked about communication complexity, and I used to opportunity to present an overview of zeta transform algorithms and applications, culminating in our SODA 2012 result from last week. [slides]
Thanks to everybody who attended, and to the nice organisers for putting me into a disarmingly charming hotel in the middle of the Latin quarter, where you couldn’t swing a dead Marsipulami without hitting a comic store. I had a splendid time.
Accepted papers for the algorithms conference SODA 2012 are announced. Best conference ever! (Compare my SODA post from last year.)
Based on my quick perusal of list of accepted papers [PDF], here’s a list of papers related to exponential time computation, together with references to online version — I’m probably missing some. Updates are welcome.
An amazing number of kernelisation (and, I presume non-kernelisation) papers. And lots and lots of exciting papers in many other fields as well.

Sour grapes
Public domain image by Chris Huh, available at Wikimedia Commons: Glass of Bell’s
Completely unrelated: list of accepted papers at SODA 2011 [PDF].

The rest of the proof is on the back. Mugshot by Rasmus Pagh.
Usually I’m not a big fan of conference merchandise—university branded ball point pens, T-shirts, bags, notepads… But boy, did I change my mind after ICALP 2010!
I saw little reason to unpack the coffee mug we got at the registration desk, and stuffed it in the conference bag. As did everybody else, I think. Only when I came home did I realise that the cup rattled. Was it broken? Intrigued, I opened the box, only to find a piece of chalk! The mug was a blackboard! We could have spent every coffee break eagerly scribbling proofs on our mugs.
Brilliant.
The Presburger Award was awarded for the first time in at the Bordeaux ICALP. The award goes to a young scientist, and the 2010 recipient is Mikolaj Bojanczyk from Warsaw for his work in automata theory, logic, and algebra.
The EATCS awards session at ICALP included this award and two more: The Gödel prize and the EATCS award. Each recipient gave a talk, and young Mikolaj faced the thankless task of appearing in a session with some of the best speakers in our field, Sanjeev Arora, Joe Mitchell, and Kurt Mehlhorn, who all gave splendid presentations.
Well, Mikolaj’s speech blew me away. Instead of explaining his research contributions, he devoted the talk to the life and work of fellow Varsovian Mojzesz Presburger (1904–1943).
Not only was this graceful, interesting, and moving, it was also extremely well presented. I say this as somebody who obsesses about presentations.
Mikolaj’s visual aids break the slides metaphor we are used to, no matter which medium—35 mm, overhead transparency, computer projector. You can see Mikolaj’s Presburger Award presentation at his website. Check out his other ICALP 2010 presentation as well: his “slides” pan and zoom about on a single, huge, dynamic canvas. I’ve tried to do something similar a few times, but this is better by orders of magnitude.
I’m at ICALP 2010 in sunny Bordeaux. I have been very busy working on two papers with colleagues who happen to attend ICALP as well, so I have missed a bunch of interesting talks on the first two days already.
I did, however, attend the business meeting, an event that combines various reports from ICALP committees with the general assembly of EATCS, the “European SIGACT.”
I normally enjoy business meetings, but ICALP business meetings are relatively stiff and mind-numbingly boring, with no discussion and no free beers. Still, let me give an incomplete and skewed summary of some of the issues that were mentioned.
ICALP publication
EATCS views ICALP as its flagship conference, and ICALP has published with Springer’s LNCS proceedings series for many years – if DBLP is to be trusted, the proceedings from the 4th ICALP (Turku, Finland, 1977) appear as LNCS volume 52. Since a few years ago, Springer has started an LNCS subline called ARCoSS (Springer page about ARCoSS) “in cooperation with” EATCS and ETAPS. These have a nicer cover.
However, it has been unclear in which sense this publication model coincides with the current preferences of the members of EATCS. Just to mention an alternative, the STACS conference now publishes with the LIPIcs series, which is Open Access in the sense that they are available on line and free of charge.
Very commendably, and to my pleasant surprise, EATCS actually implemented a member poll in the Spring of 2010 to determine our opinions on open source publication models, and in particular the outlet for ICALP’s proceedings. The results are online ([poll results at EACTS website]), but for mysterious reasons only accessible to EATCS members. It’s fair to say that there is a large majority of members that would prefer another publication model. For example, only 10% want EATCS to “Publish the proceedings of ICALP as before in a traditional print publication?” To the question “What is the publication model for scientific papers in theoretical computer science that you would prefer to see gain prominence in the near future?”, 83% respond “Open access publication as for LMCS, LIPIcs and EPTCS”
EATCS chairman Burkhard Monien reported that the EATCS Council has now approached Springer about the ICALP proceedings. According to him, Springer has made substantially better offer “very close to open access. We have discussed this carefully in the council.”
I think this is good news. However, I am less than impressed about the speed with which the process will continue. According to Monien, the result of the May 2010 poll were not sufficiently conclusive, so “We’ll ask your opinion again.” This time, there will be mercilessly concrete choices about either (1) going with LIPIcs, or (2) staying with Springer, under specific (and, I assume, new) terms. Monien explained the EATCS council wants to get this right, ICALP is a big steamer, should not go in zig-zag course, and stick to its decisions. He was unsure if the next poll will be implemented in the Fall, but promised “beginning of next year, at the latest.” I’m not holding my breath.
Still, all in all I think this is splendid news, and I’m particularly happy to the the EATCS council involving its members in an important decision process.
ICALP 2010 Organization
The report from the ICALP 2010 organizers was the usual list of statistics. I have become increasingly interested in these details after arranging ALGO 2009 myself. In total, ICALP 2010 has 292 participants, including 55 locals (the latter strikes me as a high number). 200 of these are registrants for ICALP itself, rather than one of the affiliated workshops, 147 pay the full registration fee. Only 3 Swedes and 1 Dane are registered, I wonder which I am.
This ICALP is held in the conference facilities of a large, soul-less hotel in down-town Bordeaux. I’m not a big fan of this kind of conference, and the contrast in atmosphere to the locally organised SWAT I attended in June is enormous. There’s a small lobby to hang out in, with few chairs or tables (let alone blackboards), interaction between attendees is minimal, except for the cliques one is already in. Furthermore, ICALP provides no lunches, so people scatter into small groups and look for a place to eat. Pretty much like the large US conferences.
Also, the Friday banquet is included only for full participants, meaning that many students will not be able to get the 90 Euro dinner ticket reimbursed, and consequently won’t attend. In my experience, this decision is de rigeur for Southern European ICALPs, but I think it is fundamentally misguided. The food better be spectacular.
On the other hand, the proceedings are included in the registration, which is another mistake. Many people never even remove the shrink wrap anymore, paper proceedings are just ballast. Moreover, proceedings are easy to reimburse, even for those students who honestly prefer to pay for the privilege to read the absurdly formatted 12 page LNCS amputated paper rather than reading the full version on the web.
The budget for the whole event is slightly over 100,000€, and the organizer received 2,500 emails. Apparently, EATCS maintains some for of organizer’s manual for ICALP; I’d like to see that. (I have seen the ESA/ALGO manual.) These things should be on-line, and allow for feed-back.
Programme Committees
The reports from ICALPs various programme committees included the usual absurd statistics, which were useless even by the low standards we are used to. The best paper award (Track A) went to Leslie Goldberg and Mark Jerrum’s result about about Approximating the partition function of the ferromagnetic Potts model. This is, of course, utterly splendid work. In total ICALP Track A received 229 submissions (6 were withdrawn) and accepted 60. Denmark submitted 3.33 papers, 1.17 accepted. Sweden submitted 1.83 and accepted 1.17. Again, I wonder which I am.
The programming for ICALP’s Track A has left me, and many others, completely puzzled, and looks as if it’s the result of a grep script based on paper titles. For example, ICALP had two strongly related results about Cuckoo hashing; but the results appeared in different sessions:
ICALP 2011
Michael Hoffmann presented the ICALP 2011 organisation in Zürich. icalp11.inf.ethz.ch . This seems to be an ICALP model closer to my preferences. The conference will be held in in university facilities, at something called CAB from late 19th century, with several large lecture rooms for workshops or parallel tracks, an even larger lecture hall, WLAN, and plenty of working space.
Also, there is no banquet, but rather a number of receptions with plenty of finger food and drinks. As an added benefit, registration fees are expected to be low. Of course, Zürich is “not among the cheapest places”, and prices are even higher than shown last year, because of the exchange rate between Swiss Franc and Euro, which shows high variance.
I will certainly attend, as I am one of the invited speakers. Apparently, I’m speaking on the 5th.
ICALP 2012
Artur Czumaj presented the plans for ICALP 2012, which (somewhat unusually) is already fixed two years in advance. The dates are July 9–13 2012 in Warwick, for the centenary of Alan Turing’s birth. Thus, ICALP is one of many events in the UK for the Alan Turing year, see the list of events. ICALP will be held on Warwick’s campus, including accommodation and lunches. Satellite events were said to include Wimbledon right before ICALP and the London Olympic games somewhat later.
Possibly this is the right time to start thinking about what we in the greater Copenhagen area (e.g., Sweden and Denmark, or all of Scandinavia) should be doing for the Turing year. Computer Science has far from the pop-sci clout that biology enjoys, but shouldn’t we be able to drum up at least one hundredth of the attention that Darwin got? Ideas are welcome.
For example SWAT 2012 is in the Turing year. We should start branding all our CS-related activities in 2012 as Turing-related, and hopefully concoct some more.
The SWAT conference dinner involved a boat trip to an island near Bergen, with a spectacular seafood dinner of Halibut and Wolffish. Also, initiated by Fedor Fomin, SWAT reverted back to its tradition of pressuring attendants to sing (partitioned into small groups by nationality or country of residence) after the main course. Again, the organisers managed to get the atmosphere exactly right.

{kind=link}